Hasan F. Ateş
Prof. Dr.
AI and Data Engineering
Deep learning-based adaptive system design for multi-modal image registration
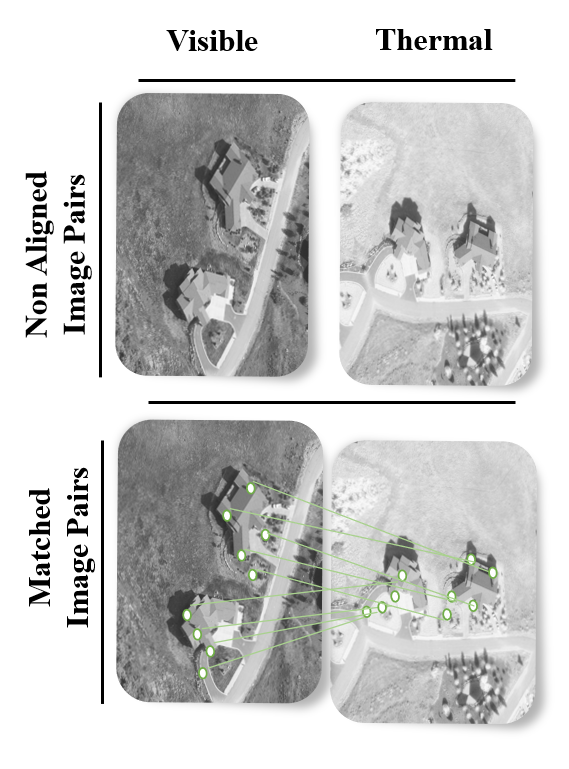
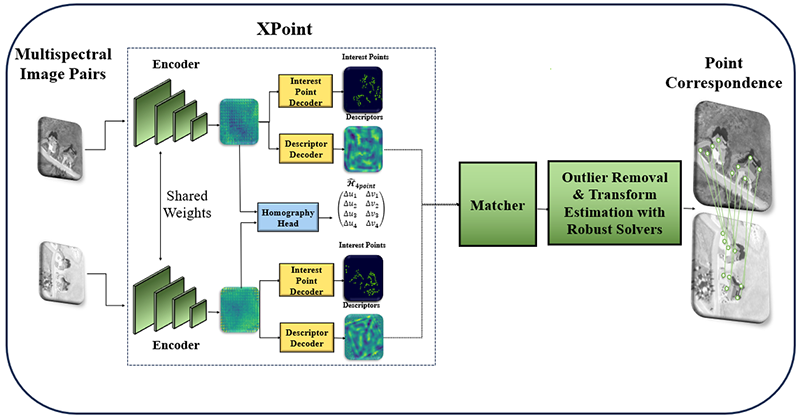
Multi-modal image matching aims to align images captured from different sensors or obtained under varying conditions and times. Despite the successes of deep learning-based solutions, the diversity and differences in multi-modal images pose significant challenges for matching. Differences in modality, resolution, illumination, and viewpoint between images make it difficult to develop a universal solution that performs well in all scenarios with a single model. In this project, an adaptive deep learning architecture based on self-supervised meta-learning is proposed to address the challenges of multi-modal image matching. The aim is for the deep learning model to be trained quickly and with minimal data for different modalities, and to adapt itself by balancing complexity and accuracy according to the difficulty of the matching task.
Initially, a large dataset covering various modalities will be created. Then, keypoint-based sparse and pixel-based dense matching solutions at different levels of complexity will be developed for the matching task. An adaptive decision mechanism will be built to select the most optimal solution in terms of speed and accuracy depending on the difficulty of the task. Matching difficulty will be determined based on the content of the two images and their differences; a deep network capable of classifying the difficulty of image pairs will also be developed. In addition to this adaptive structure, an iterative matching architecture will be tested, which applies a more advanced method when necessary, based on the performance of the initial fast matching.
Another key topic in this project is to develop fast and effective methods for adapting the system to new modalities. The model will be designed to adapt to new modalities using self-supervised learning techniques with only a few unlabeled data samples. To achieve this, meta-learning techniques will be utilized in training the adaptive system architecture. By employing model components that are trained independently of the modality and the specific matching task, the goal is to enable fine-tuning on new modalities with minimal training.
Multi-modal image matching is of great importance in various domains. In remote sensing, it facilitates the fusion of optical, SAR and infrared images, aiding environmental monitoring, disaster response, and land use classification. In medical imaging, it plays a vital role in aligning CT, MRI, and PET scans, supporting accurate diagnosis, treatment planning, and image-guided surgery. In autonomous navigation systems, it enables robust perception under varying conditions by aligning visual, thermal, and LiDAR data, thereby enhancing the safety of self-driving vehicles and UAVs. Through the applications in these and similar areas, this project aims to contribute to academic literature and initiate efforts toward new product development. Patent applications will be filed for original solutions developed in adaptive and iterative system architectures, self-supervised learning, and meta-learning, and the results will be published in international peer-reviewed journals and conferences.