Hasan Sözer
Professor
Chair of CS, Software Eng.
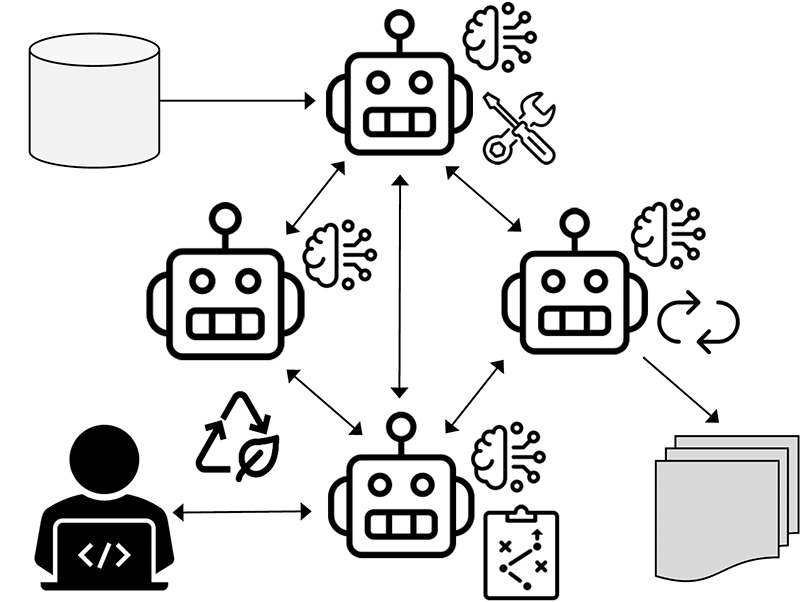
Energy-Efficient Inference of Large Language Models in Software Engineering
Large language models are increasingly used in continuous integration pipelines to automate software engineering tasks, raising concerns about energy consumption. Although research efforts primarily focus on energy consumption during the training phase, inference is more demanding in this context. We aim at empirically analyzing these demands, particularly for code generation and analysis tasks. The analysis will be performed for different hardware and model configurations using benchmark datasets to reveal key contributing factors and to characterize energy usage. These results will be used for optimizing inference energy efficiency, paving the way for scalable and sustainable use of large language models in software engineering.
Collaboration/Host: SINTEF Digital, Norway
Collaboration Model: Exchange Scheme of the ENFIELD (European Lighthouse to Manifest Trustworthy and Green AI – https://www.enfield-project.eu/) project; 3rd Open Call for the “G-AI.5 Energy-Efficient Large Language Models for Sustainable Software Engineering” challenge
Start Date: 28.07.2025